In regression analysis, heteroscedasticity (sometimes spelled heteroskedasticity) refers to the unequal scatter of residuals or error terms. Specfically, it refers to the case where there is a systematic change in the spread of the residuals over the range of measured values.
Heteroscedasticity is a problem because ordinary least squares (OLS) regression assumes that the residuals come from a population that has homoscedasticity, which means constant variance.
When heteroscedasticity is present in a regression analysis, the results of the analysis become hard to trust. Specifically, heteroscedasticity increases the variance of the regression coefficient estimates, but the regression model doesn’t pick up on this.
This makes it much more likely for a regression model to declare that a term in the model is statistically significant, when in fact it is not.
This tutorial explains how to detect heteroscedasticity, what causes heteroscedasticity, and potential ways to fix the problem of heteroscedasticity.
How to Detect Heteroscedasticity
The simplest way to detect heteroscedasticity is with a fitted value vs. residual plot.
Once you fit a regression line to a set of data, you can then create a scatterplot that shows the fitted values of the model vs. the residuals of those fitted values.
The scatterplot below shows a typical fitted value vs. residual plot in which heteroscedasticity is present.
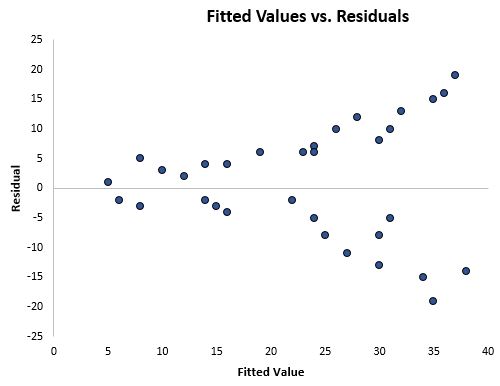
Notice how the residuals become much more spread out as the fitted values get larger. This “cone” shape is a telltale sign of heteroscedasticity.
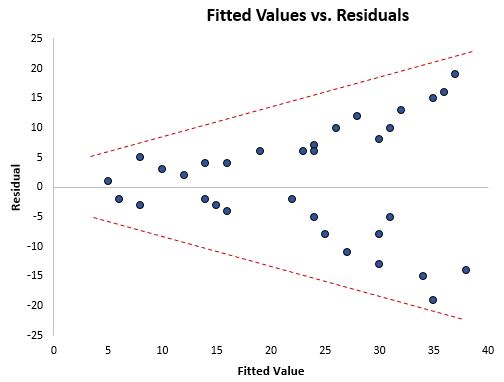
What Causes Heteroscedasticity?
Heteroscedasticity occurs naturally in datasets where there is a large range of observed data values. For example:
- Consider a dataset that includes the annual income and expenses of 100,000 people across the United States. For individuals with lower incomes, there will be lower variability in the corresponding expenses since these individuals likely only have enough money to pay for the necessities. For individuals with higher incomes, there will be higher variability in the corresponding expenses since these individuals have more money to spend if they choose to. Some higher-income individuals will choose to spend most of their income, while some may choose to be frugal and only spend a portion of their income, which is why the variability in expenses among these higher-income individuals will inherently be higher.
- Consider a dataset that includes the populations and the count of flower shops in 1,000 different cities across the United States. For cities with small populations, it may be common for only one or two flower shops to be present. But in cities with larger populations, there will be a much greater variability in the number of flower shops. These cities may have anywhere between 10 to 100 shops. This means when we create a regression analysis and use population to predict number of flower shops, there will inherently be greater variability in the residuals for the cities with higher populations.
Some datasets are simply more prone to heteroscedasticity than others.
How to Fix Heteroscedasticity
There are three common ways to fix heteroscedasticity:
1. Transform the dependent variable
One way to fix heteroscedasticity is to transform the dependent variable in some way. One common transformation is to simply take the log of the dependent variable.
For example, if we are using population size (independent variable) to predict the number of flower shops in a city (dependent variable), we may instead try to use population size to predict the log of the number of flower shops in a city.
Using the log of the dependent variable, rather than the original dependent variable, often causes heteroskedasticity to go away.
2. Redefine the dependent variable
Another way to fix heteroscedasticity is to redefine the dependent variable. One common way to do so is to use a rate for the dependent variable, rather than the raw value.
For example, instead of using the population size to predict the number of flower shops in a city, we may instead use population size to predict the number of flower shops per capita.
In most cases, this reduces the variability that naturally occurs among larger populations since we’re measuring the number of flower shops per person, rather than the sheer amount of flower shops.
3. Use weighted regression
Another way to fix heteroscedasticity is to use weighted regression. This type of regression assigns a weight to each data point based on the variance of its fitted value.
Essentially, this gives small weights to data points that have higher variances, which shrinks their squared residuals. When the proper weights are used, this can eliminate the problem of heteroscedasticity.
Conclusion
Heteroscedasticity is a fairly common problem when it comes to regression analysis because so many datasets are inherently prone to non-constant variance.
However, by using a fitted value vs. residual plot, it can be fairly easy to spot heteroscedasticity.
And through transforming the dependent variable, redefining the dependent variable, or using weighted regression, the problem of heteroscedasticity can often be eliminated.