Often researchers want to use some type of test to measure a construct like intelligence, aptitude, educational ability, etc. in individuals of some population.
When administering any type of test, it’s important that the test has reliability. In other words, it’s important that the results of a test can be reproduced under the same conditions at two different points in time.
Test-retest reliability is a specific way to measure reliability of a test and it refers to the extent that a test produces similar results over time.
We calculate the test-retest reliability by using the Pearson Correlation Coefficient, which takes on a value between -1 and 1 where:
- -1 indicates a perfectly negative linear correlation between two scores
- 0 indicates no linear correlation between two scores
- 1 indicates a perfectly positive linear correlation between two scores
For example, we may give an IQ test to 50 participants on January 1st and then give the same type of IQ test of similar difficulty to the same group of 50 participants one month later.
We could calculate the correlation of scores between the two tests to determine if the test has good test-retest reliability.
Generally a test-retest reliability correlation of at least 0.80 or higher indicates good reliability.
Example: Calculating Test-Retest Reliability
Suppose researchers give a test to 20 individuals and then give the same type of test one month later to the same 20 individuals.
Their scores are shown below:
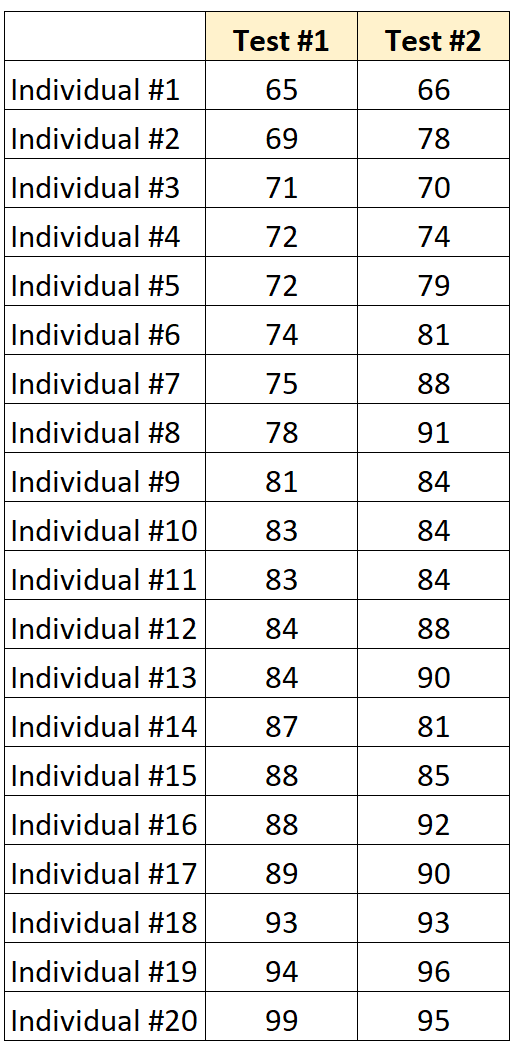
We can use a correlation calculator to find that the Pearson Correlation Coefficient between the two sets of scores is 0.836.
Since this correlation is greater than 0.80, researchers could conclude that the test has good test-retest reliability.
In other words, the test produces reliable results that can be replicated at different points in time.
Potential Bias in Test-Retest Reliability
Test-retest reliability is a useful metric to calculate, but be aware of the following potential biases that could affect this metric:
1. Practice Effect
A practice effect occurs when participants simply gets better at some test due to practice. This means they’re likely to show better results during later tests because they’ve had time to practice and improve.
The way to prevent this type of bias is to give individuals tests that are of equal difficulty but have a different variety of questions so that they can’t memorize the answers to the types of questions asked on the first test.
2. Fatigue Effect
A fatigue effect occurs when participants gets worse at some test because they get mentally drained or fatigued from taking previous tests.
The way to prevent this type of bias is to provide plenty of time in between tests (ideally weeks or even months) so that participants are fresh when taking both tests.
3. Differences in Conditions
When participants take the two tests under different conditions (i.e. different lighting, different time of day, different time allowed to complete the test, etc.) it’s possible that they score differently on the tests simply due to differences in the testing environment.
The way to prevent this type of bias is to ensure that participants take both tests under identical conditions, i.e. during the same time of day, with the same general lighting and environment, and given the same amount of time to complete the test.
Additional Resources
A Quick Introduction to Reliability Analysis
What is Split-Half Reliability?
What is Inter-rater Reliability?
What is Parallel Forms Reliability?
What is a Standard Error of Measurement?