Regression is a statistical method that can be used to determine the relationship between one or more predictor variables and a response variable.
Poisson regression is a special type of regression in which the response variable consists of “count data.” The following examples illustrate cases where Poisson regression could be used:
Example 1: Poisson regression can be used to examine the number of students who graduate from a specific college program based on their GPA upon entering the program and their gender. In this case, “number of students who graduate” is the response variable, “GPA upon entering the program” is a continuous predictor variable, and “gender” is a categorical predictor variable.
Example 2: Poisson regression can be used to examine the number of traffic accidents at a particular intersection based on weather conditions (“sunny”, “cloudy”, “rainy”) and whether or not a special event is taking place in the city (“yes” or “no”). In this case, “number of traffic accidents” is the response variable, while “weather conditions” and “special event” are both categorical predictor variables.
Example 3: Poisson regression can be used to examine the number of people ahead of you in line at a store based on time of day, day of the week, and whether or not there is a sale taking place (“yes” or “no”). In this case, “number of people ahead of you in line” is the response variable, “time of day” and “day of week” are both continuous predictor variables, and “sale taking place” is a categorical predictor variable.
Example 4: Poisson regression can be used to examine the number of people who finish a triathlon based on weather conditions (“sunny”, “cloudy”, “rainy”) and difficulty of the course (“easy”, “moderate”, “difficult”). In this case, “number of people who finish” is the response variable, while “weather conditions” and “difficulty of the course” are both categorical predictor variables.
Conducting a Poisson regression will allow you to see which predictor variables (if any) have a statistically significant effect on the response variable.
For continuous predictor variables you will be able to interpret how a one unit increase or decrease in that variable is associated with a percentage change in the counts of the response variable (e.g. “each additional point increase in GPA is associated with a 12.5% increase in the number of students who graduate”).
For categorical predictor variables you will be able to interpret the percentage change in counts of one group (e.g. number of people who finish a triathlon in sunny weather) compared to another group (e.g. number of people who finish a triathlon in rainy weather).
Assumptions of Poisson Regression
Before we can conduct a Poisson regression, we need to make sure the following assumptions are met so that our results from the Poisson regression are valid:
Assumption 1: The response variable consists of count data. In traditional linear regression, the response variable consists of continuous data. To use Poisson regression, however, our response variable needs to consists of count data that include integers of 0 or greater (e.g. 0, 1, 2, 14, 34, 49, 200, etc.). Our response variable cannot contain negative values.
Assumption 2: Observations are independent. Each observation in the dataset should be independent of one another. This means that one observation should not be able to provide any information about a different observation.
Assumption 3: The distribution of counts follows a Poisson distribution. As a result, the observed and expected counts should be similar. One simple way to test for this is to plot the expected and observed counts and see if they are similar.
Assumption 4: The mean and variance of the model are equal. This is a result of the assumption that the distribution of counts follows a Poisson distribution. For a Poisson distribution the variance has the same value as the mean. If this assumption is satisfied, then you have equidispersion. However, this assumption is often violated as overdispersion is a common problem.
Example: Poisson Regression in R
Now we will walk through an example of how to conduct Poisson regression in R.
Background
Suppose we want to know how many scholarship offers a high school baseball player in a given county receives based on their school division (“A”, “B”, or “C”) and their college entrance exam score (measured from 0 to 100).
The following code creates the dataset we will work with, which includes data on 100 baseball players:
#make this example reproducible set.seed(1) #create dataset data
Understanding the Data
Before we actually fit the Poisson regression model to this dataset, we can get a better understanding of the data by viewing the first few lines of the dataset and by using the dplyr library to run some summary statistics:
#view dimensions of dataset dim(data) #[1] 100 3 #view first six lines of dataset head(data) # offers division exam #1 0 A 73.09448 #2 0 B 67.06395 #3 0 B 65.40520 #4 0 C 79.85368 #5 0 A 72.66987 #6 0 C 64.26416 #view summary of each variable in dataset summary(data) # offers division exam # Min. :0.00 A:27 Min. :60.26 # 1st Qu.:0.00 B:38 1st Qu.:69.86 # Median :0.50 C:35 Median :75.08 # Mean :0.83 Mean :76.43 # 3rd Qu.:1.00 3rd Qu.:82.87 # Max. :4.00 Max. :93.87 #view mean exam score by number of offers library(dplyr) data %>% group_by(offers) %>% summarise(mean_exam = mean(exam)) # A tibble: 5 x 2 # offers mean_exam # #1 0 70.0 #2 1 80.8 #3 2 86.8 #4 3 83.9 #5 4 87.9
From the output above we can observe the following:
- There are 100 rows and 3 columns in the dataset
- The minimum number of offers received by a player was zero, the max was four, and the mean was 0.83.
- In this dataset, there are 27 players from division “A”, 38 players from division “B”, and 35 players from division “C.”
- The minimum exam score was a 60.26, the max was 93.87, and the mean was 76.43.
- In general, players who received more scholarship offers tended to earn higher exam scores (e.g. the mean exam score for players who received 0 offers was 70.0 and the mean exam score for players who received 4 offers was 87.9).
We can also create a histogram to visualize the number of offers received by players based on division:
#load ggplot2 package library(ggplot2) #create histogram ggplot(data, aes(offers, fill = division)) + geom_histogram(binwidth=.5, position="dodge")
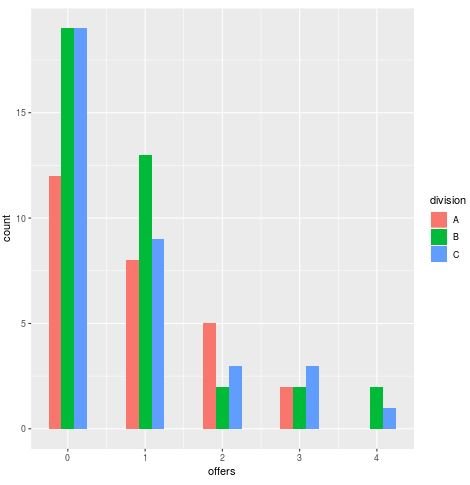
We can see that most players received either zero or one offer. This is typical for datasets that follow Poisson distributions: a decent chunk of response values are zero.
Fitting the Poisson Regression Model
Next, we can fit the model using the glm() function and specifying that we’d like to use family = “poisson” for the model:
#fit the model model family = "poisson", data = data) #view model output summary(model) #Call: #glm(formula = offers ~ division + exam, family = "poisson", data = data) # #Deviance Residuals: # Min 1Q Median 3Q Max #-1.2562 -0.8467 -0.5657 0.3846 2.5033 # #Coefficients: # Estimate Std. Error z value Pr(>|z|) #(Intercept) -7.90602 1.13597 -6.960 3.41e-12 *** #divisionB 0.17566 0.27257 0.644 0.519 #divisionC -0.05251 0.27819 -0.189 0.850 #exam 0.09548 0.01322 7.221 5.15e-13 *** #--- #Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 # #(Dispersion parameter for poisson family taken to be 1) # # Null deviance: 138.069 on 99 degrees of freedom #Residual deviance: 79.247 on 96 degrees of freedom #AIC: 204.12 # #Number of Fisher Scoring iterations: 5
From the output we can observe the following:
- The Poisson regression coefficients, the standard error of the estimates, the z-scores, and the corresponding p-values are all provided.
- The coefficient for exam is 0.09548, which indicates that the expected log count for number of offers for a one-unit increase in exam is 0.09548. An easier way to interpret this is to take the exponentiated value, that is e0.09548 = 1.10. This means there is a 10% increase in the number of offers received for each additional point scored on the entrance exam.
- The coefficient for divisionB is 0.1756, which indicates that the expected log count for number of offers for a player in division B is 0.1756 higher than for a player in division A. An easier way to interpret this is to take the exponentiated value, that is e0.1756 = 1.19. This means players in division B receive 19% more offers than players in division A. Note that this difference is not statistically significant (p = 0.519).
- The coefficient for divisionC is -0.05251, which indicates that the expected log count for number of offers for a player in division C is 0.05251 lower than for a player in division A. An easier way to interpret this is to take the exponentiated value, that is e0.05251 = 0.94. This means players in division C receive 6% fewer offers than players in division A. Note that this difference is not statistically significant (p = 850).
Information on the deviance of the model is also provided. We are most interested in the residual deviance, which has a value of 79.247 on 96 degrees of freedom. Using these numbers, we can conduct a Chi-Square goodness of fit test to see if the model fits the data. The following code illustrates how to conduct this test:
pchisq(79.24679, 96, lower.tail = FALSE) #[1] 0.8922676
The p-value for this test is 0.89, which is much larger than the significance level of 0.05. We can conclude that the data fits the model reasonably well.
Visualizing the Results
We can also create a plot that shows the predicted number of scholarship offers received based on division and entrance exam score using the following code:
#find predicted number of offers using the fitted Poisson regression model
data$phat #create plot that shows number of offers based on division and exam score
ggplot(data, aes(x = exam, y = phat, color = division)) +
geom_point(aes(y = offers), alpha = .7, position = position_jitter(h = .2)) +
geom_line() +
labs(x = "Entrance Exam Score", y = "Expected number of scholarship offers")

The plot shows the highest number of expected scholarship offers for players who score high on the entrance exam score. In addition, we can see that players from division B (the green line) are expected to get more offers in general than players from either division A or division C.
Reporting the Results
Lastly, we can report the results of the regression in such a way that summarizes our findings:
A Poisson regression was run to predict the number of scholarship offers received by baseball players based on division and entrance exam scores. For each additional point scored on the entrance exam, there is a 10% increase in the number of offers received (p . Division was found to not be statistically significant.
Additional Resources
Introduction to Simple Linear Regression
Introduction to Multiple Linear Regression
An Introduction to Polynomial Regression