You can use proc sort in SAS to quickly remove duplicate rows from a dataset.
This procedure uses the following basic syntax:
proc sort data=original_data out=no_dups_data nodupkey;
by _all_;
run;
Note that the by argument specifies which columns to analyze when removing duplicates.
The following examples show how to remove duplicates from the following dataset in SAS:
/*create dataset*/
data original_data;
input team $ position $ points;
datalines;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run;
/*view dataset*/
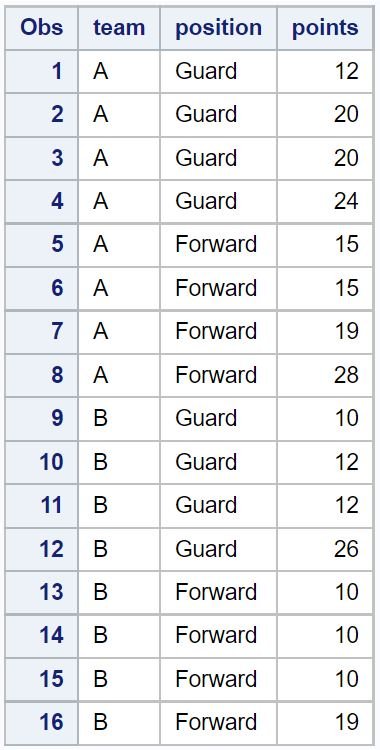
proc print data=original_data;
Example 1: Remove Duplicates from All Columns
We can use the following code to remove rows that have duplicate values across all columns of the dataset:
/*create dataset with no duplicate rows*/
proc sort data=original_data out=no_dups_data nodupkey;
by _all_;
run;
/*view dataset with no duplicate rows*/
proc print data=no_dups_data;
Notice that a total of five duplicate rows have been removed from the original dataset.
Example 2: Remove Duplicates from Specific Columns
We can use the by argument to specify which columns to look at when removing duplicates.
For example, the following code removes rows that have duplicate values in the team and position columns:
/*create dataset with no duplicate rows in team and position columns*/
proc sort data=original_data out=no_dups_data nodupkey;
by team position;
run;
/*view dataset with no duplicate rows in team and position columns*/
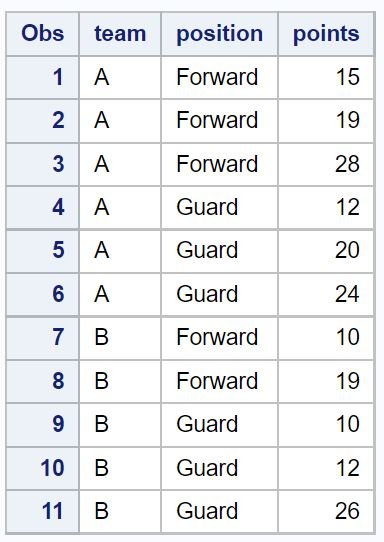
proc print data=no_dups_data;

Only four rows are left in the dataset after removing the rows that had duplicate values in the team and position columns.
Additional Resources
The following tutorials explain how to perform other common operations in SAS:
How to Normalize Data in SAS
How to Identify Outliers in SAS
How to Use Proc Summary in SAS
How to Create Frequency Tables in SAS