In statistics, raw data refers to data that has been collected directly from a primary source and has not been processed in any way.
In any type of data analysis project, the first step is gathering raw data. Once this data has been gathered, it can then be cleaned, transformed, summarized, and visualized.
The whole point of gathering raw data is to eventually use it to gain a better understanding of some phenomena or use it to build some type of predictive model.
The following example illustrates how raw data might be collected and used in real life.
Example: Collecting & Using Raw Data
One field in which raw data is often collected is sports. For example, raw data might be collected for various statistics for professional basketball players.
Step 1: Collect Raw Data
Imagine that a basketball scout collects the following raw data for 10 players on a professional basketball team: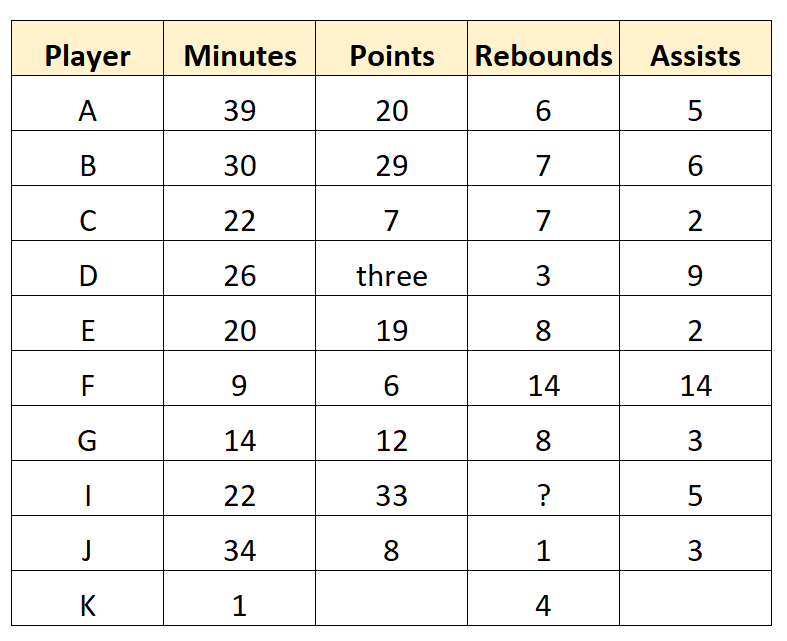
This dataset represents the raw data because it’s collected directly by the scout and it hasn’t been cleaned or processed in any way.
Step 2: Clean Raw Data
Before using this data to create summary tables, charts, or anything else, the scout would first remove any missing values and clean up any “dirty” data values.
For example, we can spot several values in the dataset that need to be transformed or removed:
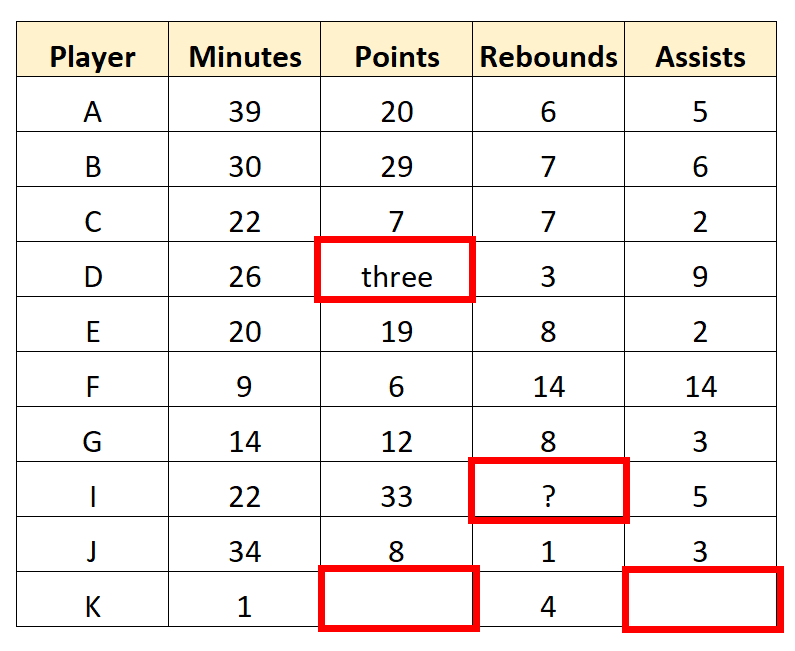
The scout may decide to remove the last row entirely since it has multiple missing values. He may then clean up the character values in the dataset as well to end up with the following “clean” data:
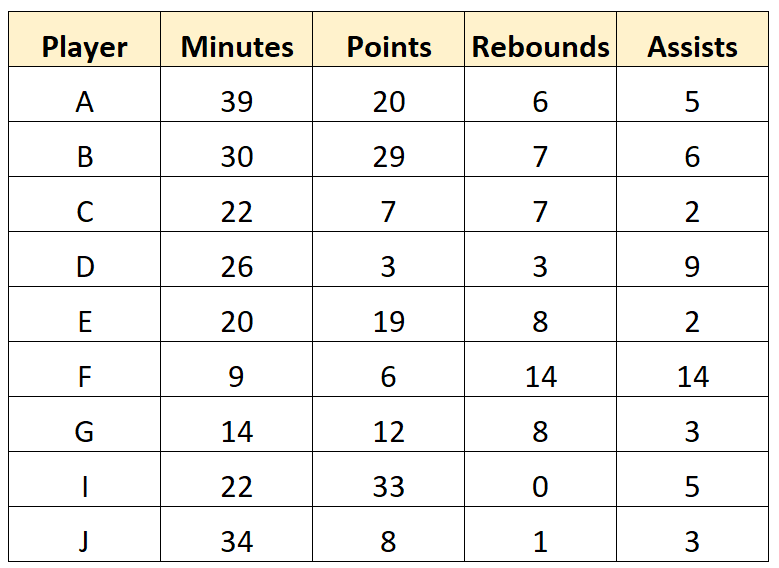
Step 3: Summarize Data
Once the data has been cleaned, the scout may then summarize each variable in the dataset. For example, he could calculate the following summary statistics for the “Minutes” variable:
- Mean: 24 minutes
- Median: 22 minutes
- Standard deviation: 9.45 minutes
Step 4: Visualize Data
The scout may then visualize the variables in the dataset to gain a better understanding of the data values.
For example, he could create the following bar chart to visualize the total minutes played by each player:
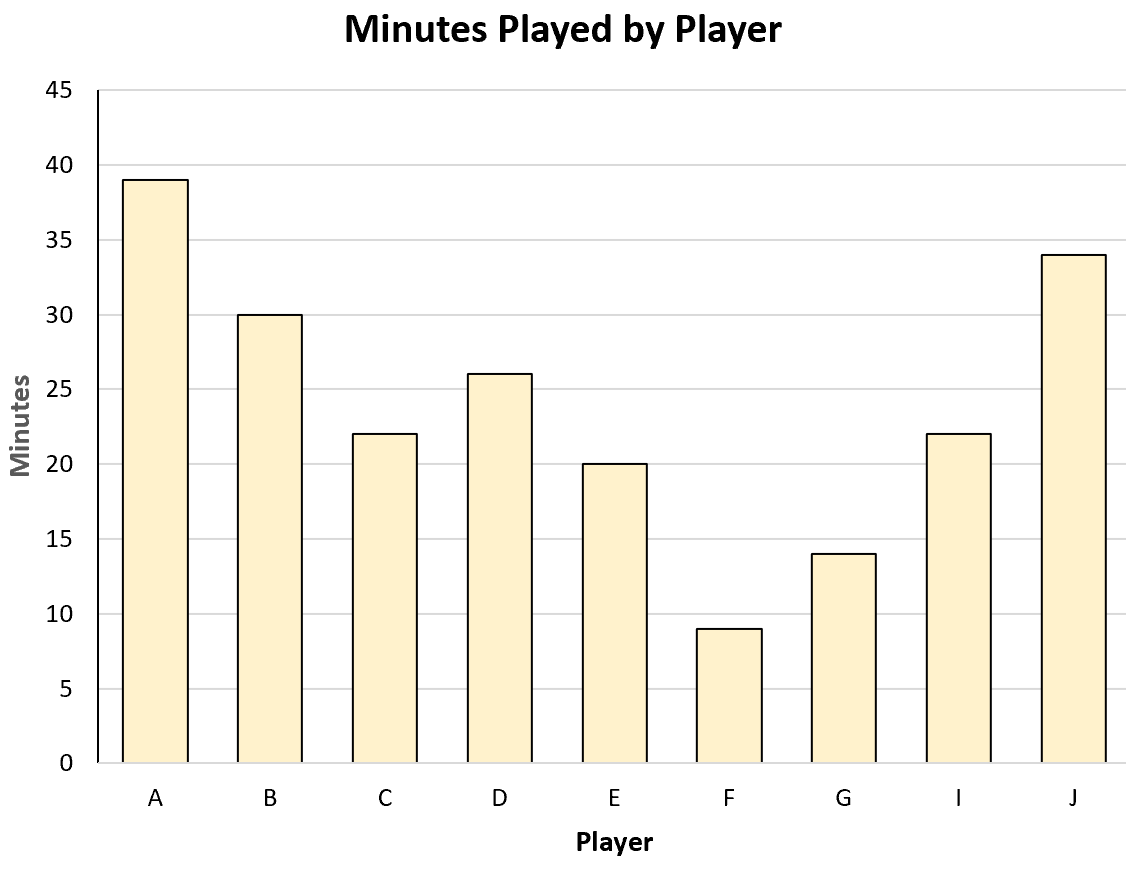
Or he could create the following scatterplot to visualize the relationship between minutes played and points scored:
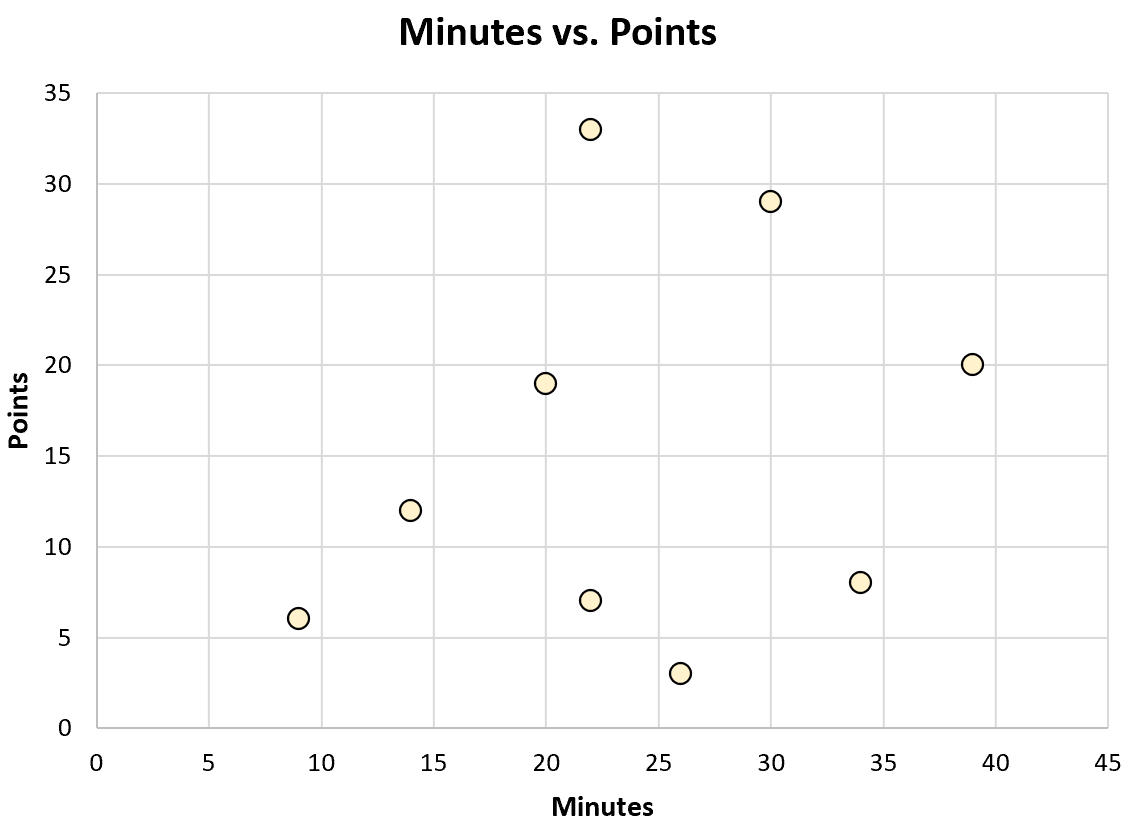
Each of these types of charts can help him gain an understanding of the data.
Step 5: Use Data to Build a Model
Lastly, once the data has been cleaned the scout may decide to fit some type of predictive model.
For example, he may fit a simple linear regression model and use minutes played to predict total points scored by each player.
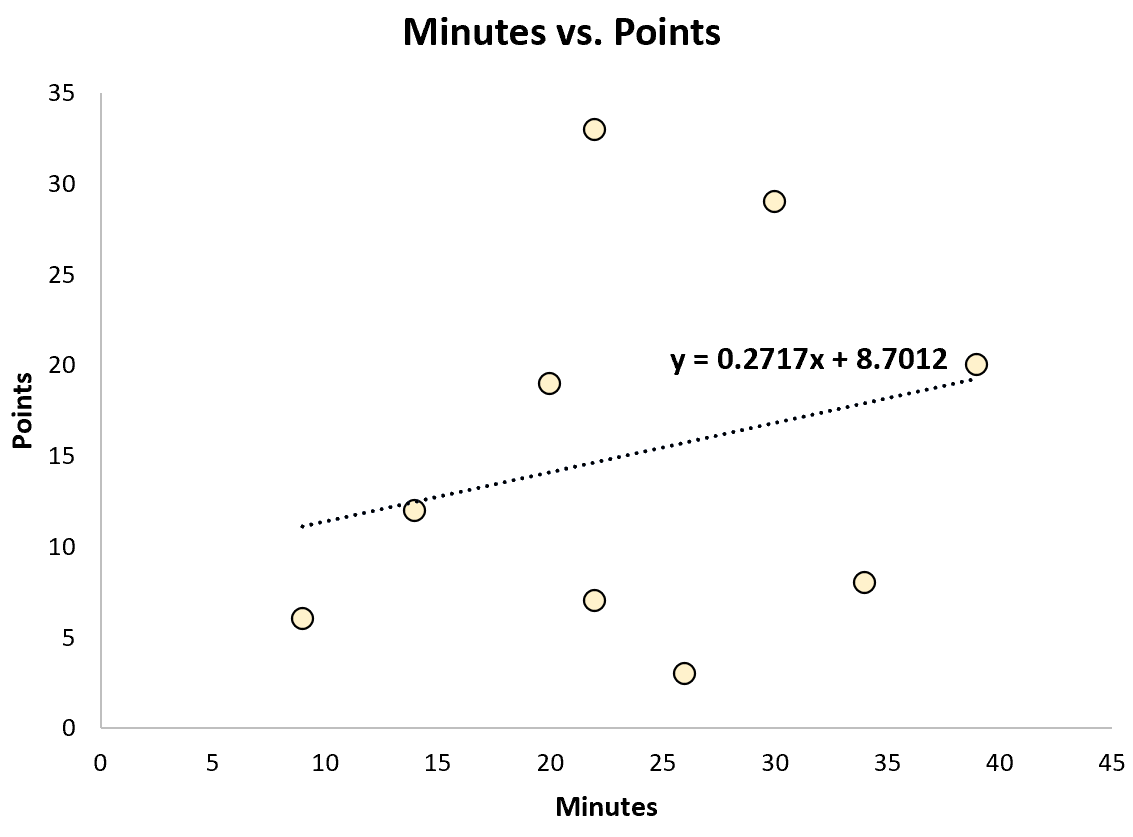
The fitted regression equation is:
Points = 8.7012 + 0.2717*(minutes)
The scout could then use this equation to predict the number of points a player will score based on the number of minutes played. For example, an athlete that plays 30 minutes is predicted to score 16.85 points:
Points = 8.7012 + 0.2717*(30) = 16.85
Additional Resources
Why is Statistics Important?
Why is Sample Size Important in Statistics?
What is an Observation in Statistics?
What is Tabular Data in Statistics?